\item Η κάθε ακολουθία $m$ αποτελείται από ανταλλαγές μεταξύ γειτόνων, των οποίων η απόσταση ξεκινάει από $2^{m-1}$ και μειώνεται με διαδοχικές ακέραιες διαιρέσεις με το 2, εωσότου γίνει $1$: $2^{m-1}, 2^{m-2}, ..., 1$.
\item Η κάθε ακολουθία $m$ αποτελείται από ανταλλαγές μεταξύ γειτόνων, των οποίων η απόσταση ξεκινάει από $2^{m-1}$ και μειώνεται με διαδοχικές ακέραιες διαιρέσεις με το 2, εωσότου γίνει $1$ ($2^{m-1}, 2^{m-2}, ..., 1$).
\item Οι ανταλλαγές χωρίζουν τα μεγαλύτερα και τα μικρότερα στοιχεία με στόχο στο τέλος της κάθε ακολουθίας τα στοιχεία του πίνακα να αποτελούν διαδοχικές διτονικές ακολουθίες.
Μέτά την πρώτη ακολουθία ανταλλαγών να έχουμε $\frac{N}{2}$ διτονικές ακολουθίες, μετά την δεύτερη $\frac{N}{4}$ ακολουθίες και ούτω κάθε εξής, έως ότου στην τελευταία να έχουμε $\frac{N}{2N} = \frac{1}{2}$ διτονική, δηλαδή μια πλήρως ταξινομημένη λίστα.
Βλέπουμε λοιπόν πως \textbf{ο αλγόριθμος είναι πρακτικά ο ίδιος}, απλώς \textbf{οι ανταλλαγές} στα βήματα εντός του block \textbf{λαμβάνουν χώρα στη shared μνήμη} αντί της global.
Επίσης πολύ εύκολα μπορούμε να αντιληφθούμε πως οι απαιτήσεις σε shared μνήμη είναι δυο φορές το μέγεθος των blocks.
Τη μνήμη αυτή τη δεσμεύουμε δυναμικά μέσω ορίσματος στον kernel \textit{inBlockStep<<<Nbl, Nth, kernelMemSize>>>()}.
Τη μνήμη αυτή τη δεσμεύουμε δυναμικά μέσω ορίσματος στον kernel \textit{inBlockStep\texttt{<<<}Nbl, Nth, kernelMemSize\texttt{>>>}()}.
\par
Η αλλαγή για την δεύτερη έκδοση βρίσκεται επί της ουσίας στη συνάρτηση \textit{inBlockStep()}.
Η συνάρτηση \textit{interBlockStep()} παραμένει ως έχει, καθώς εργάζεται με αποστάσεις μεγαλύτερες αυτών που χωρούν στη shared μνήμη που έχουμε δεσμεύσει για τα blocks.
Αν και καταβάλαμε φιλότιμη προσπάθεια να μειώσουμε τις εντολές, τελικά αυτή η κατεύθυνση δεν μας οδήγησε πουθενά.
Αντίθετά για τα άλλα δύο σημεία προσπαθήσαμε κάποιες λύσεις.
\subsection{Ελαχιστοποίηση των αρχικών \textit{inBlockStep()} κλήσεων} \label{sec:Opt_prephase}
\subsection{Ελαχιστοποίηση των αρχικών κλήσεων της \textit{inBlockStep()} - Prephase} \label{sec:Opt_prephase}
Μια βελτιστοποίηση που σκεφτήκαμε και δεν έχει να κάνει με το shared memory optimization είναι ο αριθμός των \textit{inBlockStep()} στην αρχή του αλγόριθμου.
Αν προσέξει κανείς το σχήμα \ref{fig:V1Unrolling} εύκολα θα παρατηρήσει πως στην αρχή του αλγόριθμου ο διπλός βρόχος περιέχει βήματα που χωράνε εξολοκλήρου στο block.
Παρόλα αυτά γίνονται ξεχωριστές κλήσεις στην \textit{inBlockStep()} χωρίς να μεσολαβεί κάποια κλήση στην \textit{interBlockStep()}.
Μπορούμε έτσι να \textbf{συνενώσουμε όλες αυτές τις πρώτες ξεχωριστές κλήσεις της \textit{inBlockStep()} σε μία συνάρτηση} η οποία δεν χρειάζεται να επιστρέφει παρά μόνο όταν τα βήματα του βρόχου φτάσουν να χρειαστεί να καλέσουν την πρώτη \textit{interBlockStep()}.
Η συνάρτηση αυτή είναι η \textit{prephace()}.
Η συνάρτηση αυτή είναι η \textit{prephase()}.
\par
Πριν αποδεχτούμε βέβαια αυτή τη βελτιστοποίηση έπρεπε πρώτα να την μετρήσουμε.
Η έκδοση στην οποία δοκιμάστηκε αυτή η προσέγγιση είναι η RC2 και ο αναγνώστης μπορεί να τη βρει στο αποθετήριο της εργασίας.
Το οποίο για πίνακα μεγέθους q=24 θα εκτελέσει την ταξινόμηση 5 φορές, θα ελέγξει την εγκυρότητά της και θα εκτυπώσει τον ενδιάμεσο χρόνο, χρησιμοποιώντας στην πρώτη εντολή την έκδοση v1 και στη δεύτερη την έκδοση v2 αλλά και block size 512 threads.
Δίνοντας το όρισμα \texttt{-h} ο χρήστης μπορεί να δει όλες τι επιλογές εκτέλεσης και μια μικρή τεκμηρίωση ώστε να πειραματιστεί.
\par
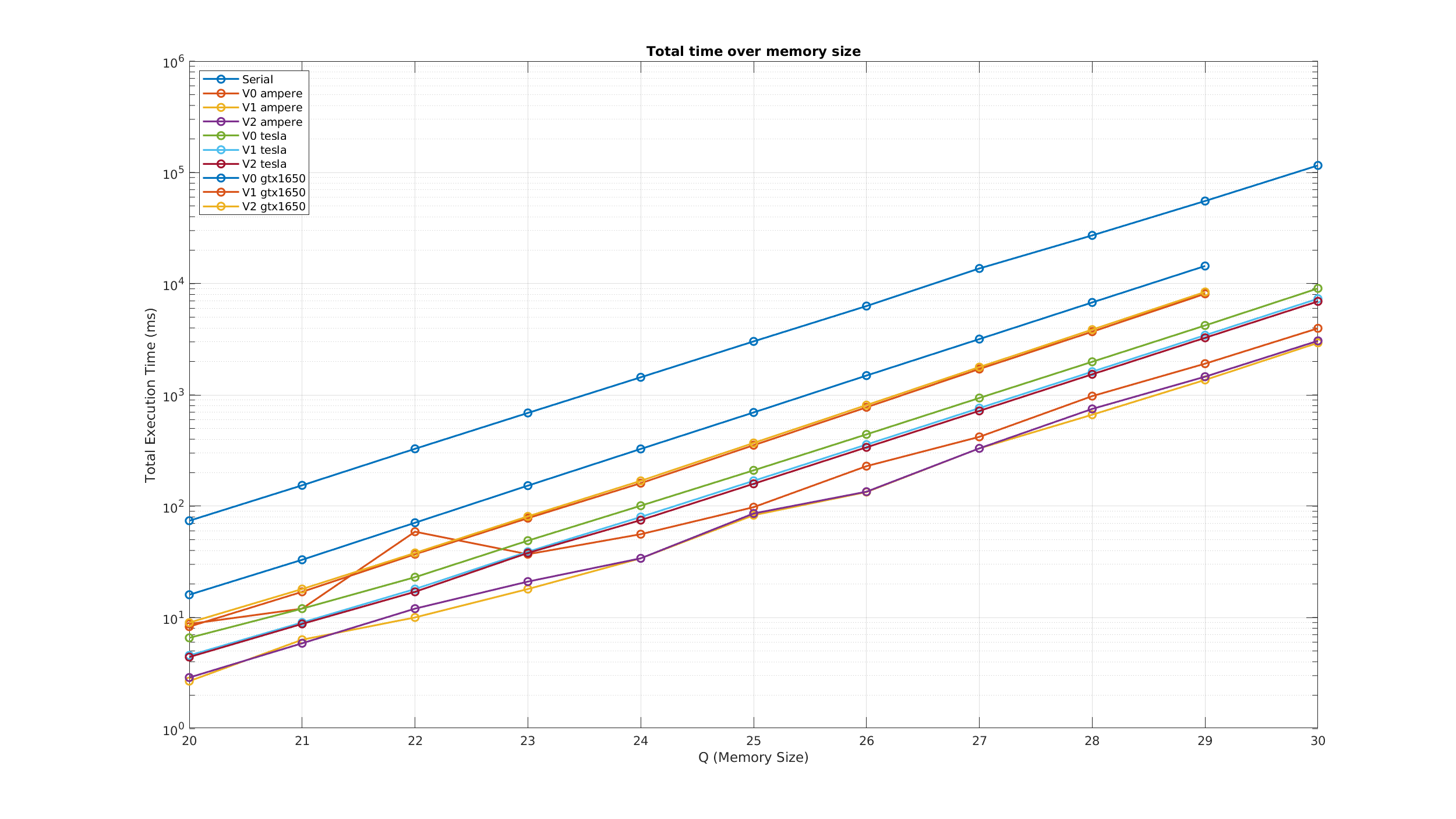
Παρακάτω παραθέτουμε τα αποτελέσματα στους τελικούς χρόνους από τη συστοιχία ampere, gpu(tesla), αλλά και από μια κάρτα GTX1650, όπου κρατήσαμε τον ενδιάμεσο χρόνο από 7 εκτελέσεις.
Παρακάτω παραθέτουμε τα γραφήματα και τα αποτελέσματα στους τελικούς χρόνους από τη συστοιχία ampere, gpu(tesla), αλλά και από μια κάρτα GTX1650, όπου κρατήσαμε τον ενδιάμεσο χρόνο από 7 εκτελέσεις.
\InsertFigure{H}{1.025}{fig:TotalTime}{../matlab/total_time_plot}{Συνολικός χρόνος εκτέλεσης της ταξινόμησης (Με μεταφορά δεδομένων).}
\InsertFigure{H}{1.025}{fig:SortTime}{../matlab/sort_time_plot}{Χρόνος εκτέλεσης της ταξινόμησης (Χωρίς μεταφορά δεδομένων).}
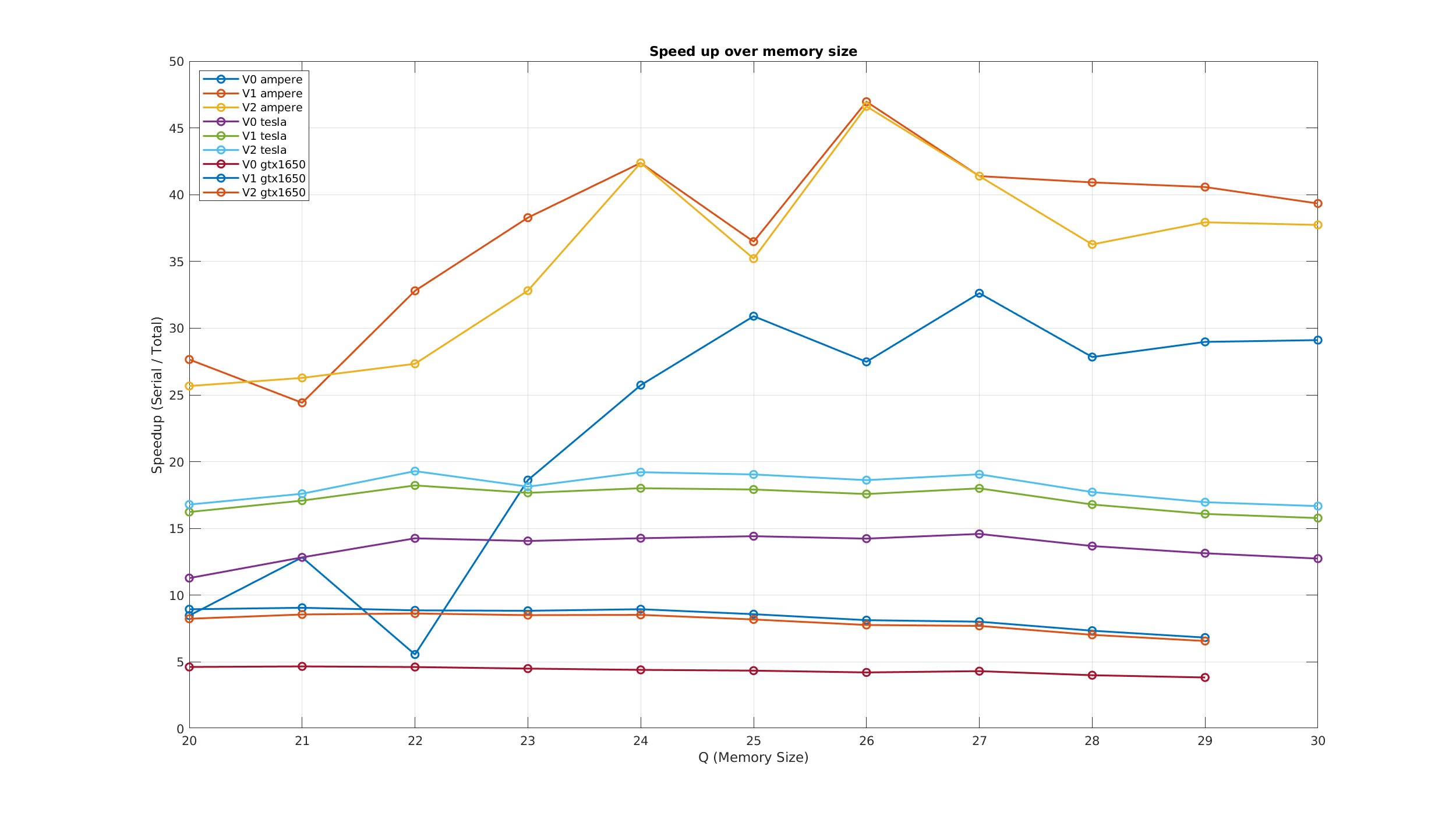
\InsertFigure{H}{1.025}{fig:SpeedUp}{../matlab/speedup_plot}{Επιτάχυνση σε σχέση με τη σειριακή έκδοση (Συστοιχία AMD 7742).}
\caption{Μέρος των τελικών μετρήσεων στη συστοιχία.}
\label{tab:Final_Reults}
\end{table}
\subsection{Συμπεράσματα}
Από τα διαγράμματα και τις μετρήσεις βλέπουμε πως:
\begin{itemize}
\item Η έκδοση που επιταχύνεται από την GPU σε σχέση με την εκτέλεση στη CPU του ίδιου μηχανήματος είναι \textbf{γρηγορότερη ακόμα και για μικρό μέγεθος δεδομένων}.
Φυσικά, εδώ θα μπορούσαμε να συγκρίνουμε μια σειριακή εκτέλεση εντός GPU, αλλά αυτό θα εμφάνιζε κυρίως το θεωρητικό και μαθηματικό πλεονέκτημα της παραλληλοποίησης και θα εξαρτώνταν κυρίως από των αριθμό των παράλληλων threads.
Αντίθετα η σύγκριση με τη CPU έγινε για να αποκτηθεί μια αίσθηση από ένα πιο πιθανό σενάριο ανάγκης για επιτάχυνση από GPU.
\item Η κάρτα \textbf{Tesla P100-PCIE-12GB} της συστοιχίας gpu παρουσιάζει \textbf{διαφορετική συμπεριφορά για την έκδοση V2}, σε σχέση με την NVIDIA A100-SXM4-40GB της ampere, αλλά και της GTX1650.
\item Επίσης η \textbf{υπεροχή} της Α100 στις επιδόσεις \textbf{στη μεταφορά δεδομένων} φαίνονται έντονα στο σχήμα \ref{fig:SpeedUp}, όπου η κάρτα κερδίζει αρκετό έδαφος καθώς το μέγεθος προς ταξινόμηση μεγαλώνει.
\end{itemize}
\section{Σύνοψη}
Κλείνοντας να πούμε πως προσπαθήσαμε να παρουσιάσουμε ένα σχετικά αποδοτικό αλγόριθμο δίνοντας βάση στην βελτιστοποίηση μέσω ανάλυσης.
Ξεκινώντας από την έκδοση V0 η οποία χρησιμοποιεί απλή παραλληλοποίηση, περάσαμε στη V1 που μειώνει τις kernel κλήσεις μέσω loop unrolling και στη V2 που αξιοποιεί shared memory.
Μέσα από προφίλ εκτελέσεων και ανάλυση επιδόσεων, προέκυψε αρχικά το συμπέρασμα ότι η V2 παρουσιάζει δικαιολογημένες αποκλίσεις, και στη συνέχεια η βελτιστοποίηση του prephase.
Οι πειραματικές μετρήσεις που πραγματοποιήθηκαν σε διάφορες αρχιτεκτονικές GPU (Ampere A100, Tesla P100, GTX 1650) επιβεβαίωσαν την αποτελεσματικότητα της παραλληλοποίησης έναντι μιας σειριακής εκτέλεσης σε CPU (AMD 7742), με σημαντικό speedup, ειδικά για μεγάλα dataset sizes.
\par
Τέλος, αν και δεν καταφέραμε να υλοποιήσουμε όλες μας τις ιδέες, θεωρούμε πως ασχοληθήκαμε με κάποιες βελτιστοποιήσεις που ίσως να αξίζουν περισσότερης διερεύνησης, πέρα από το πλαίσιο της εργασίας.


{kind=link}

{kind=link}
{kind=link}